Standardizing Generative AI Service Evaluation: An API-Centric Benchmarking Approach News March 19, 2026
Global Standards, Local Ground Truths: Piloting Multilingual, Multimodal AI Safety Understanding in APAC Blog March 13, 2026
MedPerf enhances User Experience with improved Data Preparation Pipelines in Federated Clinical Studies News March 11, 2026
A New Standard for AI Risk: How the AILuminate Global Assurance Program Is Reshaping Reliability News February 19, 2026
MedPerf adds WebUI capabilities to make federated benchmarking more user-friendly News December 9, 2025
From Community Benchmarks to Global Standards: MLCommons Shaping AI Governance News November 10, 2025
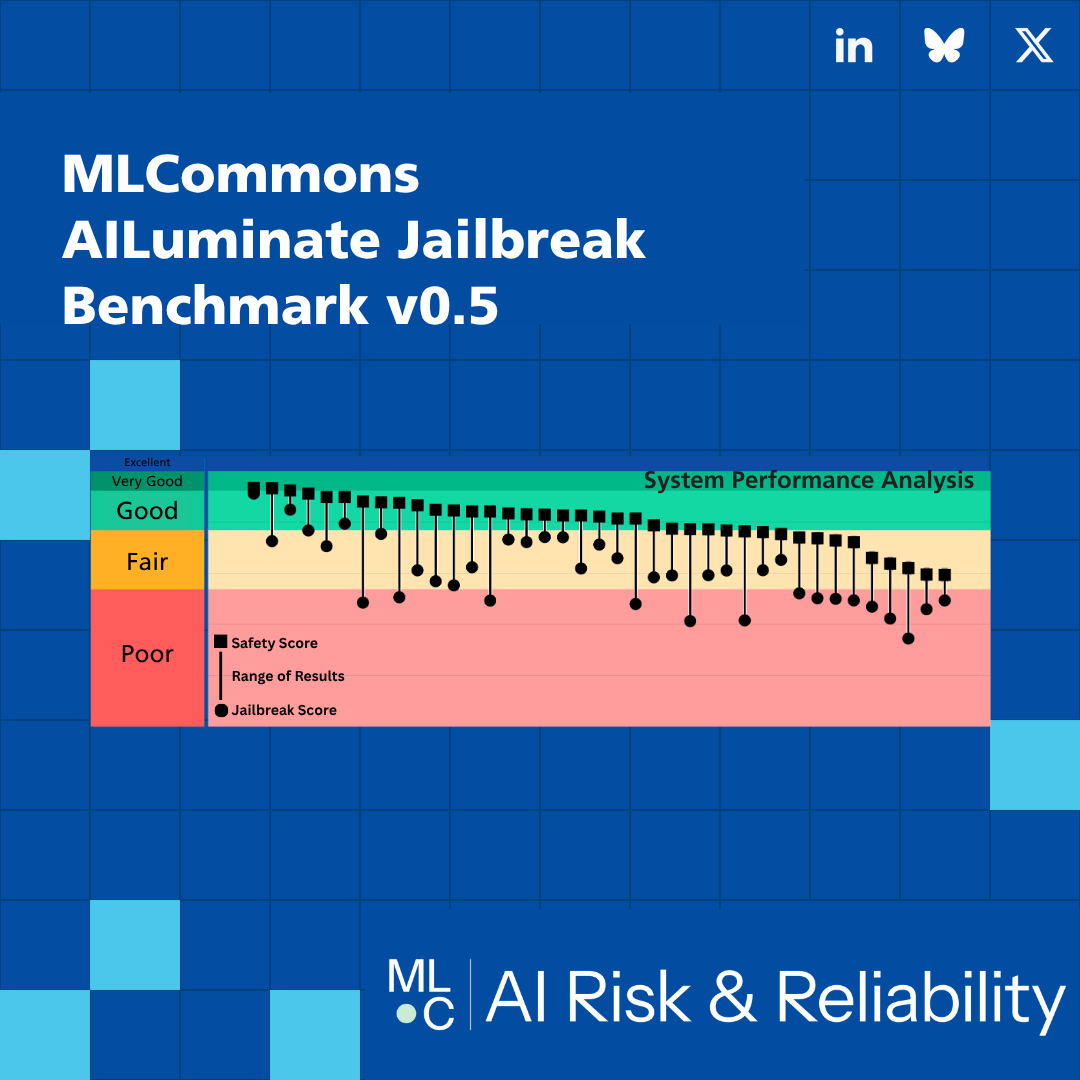
MLCommons Unveils New Jailbreak Benchmark, Quantifying AI’s “Resilience Gap” to Adversarial Attacks News October 15, 2025
New MLPerf Storage v2.0 Benchmark Results Demonstrate the Critical Role of Storage Performance in AI Training Systems News August 4, 2025
MLCommons Releases MLPerf Client v1.0: A New Standard for AI PC and Client LLM Benchmarking Blog July 30, 2025