Hi All.
I’m new here.
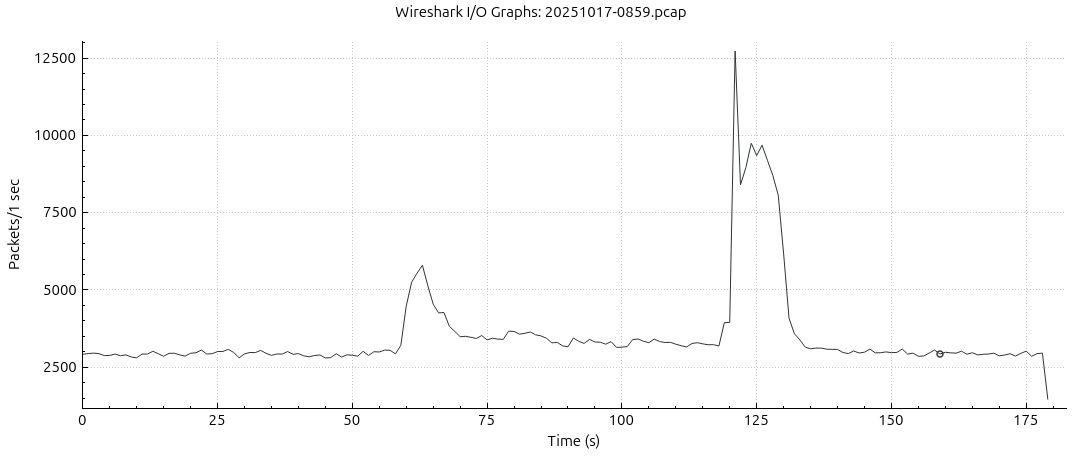
I brought my first server up a week ago. And I see hourly, on the hour, “abuse” of my server. If, and that is a big if, I have set my appliance up correctly, then it can handle 40K requests per second, and it still logs “Excessive traffic on port X” one minute past the hour, about 50% of the time. This seems to not be caused by DNS, but by abusive users in my case?
Looking at pfTop on my firewall I see high request rates from some IPs, but I don’t know if I’m misinterpreting the data. And I have been unable to catch the hourly overload in pfTop, as I forget to look on the hour.
Example from logs:
Oct 15 14:01:13 TimeProvider alarmd: Id: 112, Index: 002, Severity: major, Alarm: set, Msg: Excessive traffic on Ethernet port 2
Oct 15 14:01:13 TimeProvider alarmd: Id: 112, Index: 003, Severity: major, Alarm: set, Msg: Excessive traffic on Ethernet port 3
Oct 15 14:01:25 TimeProvider alarmd: Id: 112, Index: 002, Severity: major, Alarm: clear, Msg: Excessive traffic on Ethernet port 2 cleared
Oct 15 14:01:25 TimeProvider alarmd: Id: 112, Index: 003, Severity: major, Alarm: clear, Msg: Excessive traffic on Ethernet port 3 cleared
As this is an appliance(Microchip TimeProvider 4100) I’m unable to get real request rates. I plan to move the NTP traffic to it’s own firewall port to track it on the firewall.
The TP4100, according to tech specs, can handle 20K pps per port. I am currently load balancing between two ports. I will try to bring more ports online, but it uses SFP ports which makes it a bit hard.
Thank you,
Errol