Welcome to MIT HAN Lab! We specialize in efficient generative AI, including large language models (LLMs), multi-modal models (VLMs/VLAs), and diffusion models. Today’s foundation models are remarkably powerful but prohibitively costly in terms of computation, energy, and scalability. At MIT HAN Lab, we integrate algorithm–system co-design to push the frontier of AI efficiency and performance. Our research spans the entire AI stack—from pre-training and post-training to model compression and deployment—bridging fundamental breakthroughs with real-world applications. By rethinking how AI is designed with GPU efficiency in mind, we aim to make generative AI faster, greener, and more accessible.
Alumni: Ji Lin (OpenAI), Hanrui Wang (Co-Founder @Eigen AI), Zhijian Liu (assistant professor @UCSD), Han Cai (NVIDIA Research), Haotian Tang (Google Deepmind->Meta), Yujun Lin (NVIDIA Research), Wei-Chen Wang (Co-Founder @Eigen AI), Wei-Ming Chen (NVIDIA).
Accelerating LLM and Generative AI [slides]:





HART has been highlighted by MIT news: AI tool generates high-quality images faster than state-of-the-art approaches!
🔥⚡ We release TinyChat 2.0, the latest version with significant advancements in prefilling speed of Edge LLMs and VLMs, 1.5-1.7x faster than the previous version of TinyChat. Please refer to our blog for more details.
DistriFusion is integrated in NVIDIA's TensorRT-LLM for distributed inference on high-resolution image generation.
🔥 NVIDIA TensorRT-LLM, AMD, Google Vertex AI, Amazon Sagemaker, Intel Neural Compressor, FastChat, vLLM, HuggingFace TGI, and LMDeploy adopt AWQ to improve LLM serving efficiency. Our AWQ models on HuggingFace has received over 6 million downloads.
Congrats on graduation! Cheers on the next move: Zhijian Liu: assistant professor at UCSD, Hanrui Wang: assistant professor at UCLA, Ji Lin: OpenAI, Han Cai: NVIDIA Research, Wei-Chen Wang (postdoc): Amazon, Wei-Ming Chen (postdoc): NVIDIA.
We show SmoothQuant can enable W8A8 quantization for Llama-1/2, Falcon, Mistral, and Mixtral models with negligible loss.
We supported VILA Vision Languague Models in AWQ & TinyChat! Check our latest demos with multi-image inputs!
StreamingLLM is integrated by HPC-AI Tech SwiftInfer to support infinite input length for LLM inference.
StreamingLLM is integrated by CMU, UW, and OctoAI, enabling endless and efficient LLM generation on iPhone!
Congrats Ji Lin completed and defended his PhD thesis: "Efficient Deep Learning Computing: From TinyML to Large Language Model". Ji joined OpenAI after graduation.
AWQ is integrate by NVIDIA TensorRT-LLM, can fit Falcon-180B on a single H200GPU with INT4 AWQ, and 6.7x faster Llama-70B over A100.
🔥 AWQ is now integrated natively in Hugging Face transformers through from_pretrained. You can either load quantized models from the Hub or your own HF quantized models.
Attention Sinks, an library from community enables StreamingLLM on more Huggingface LLMs. blog.
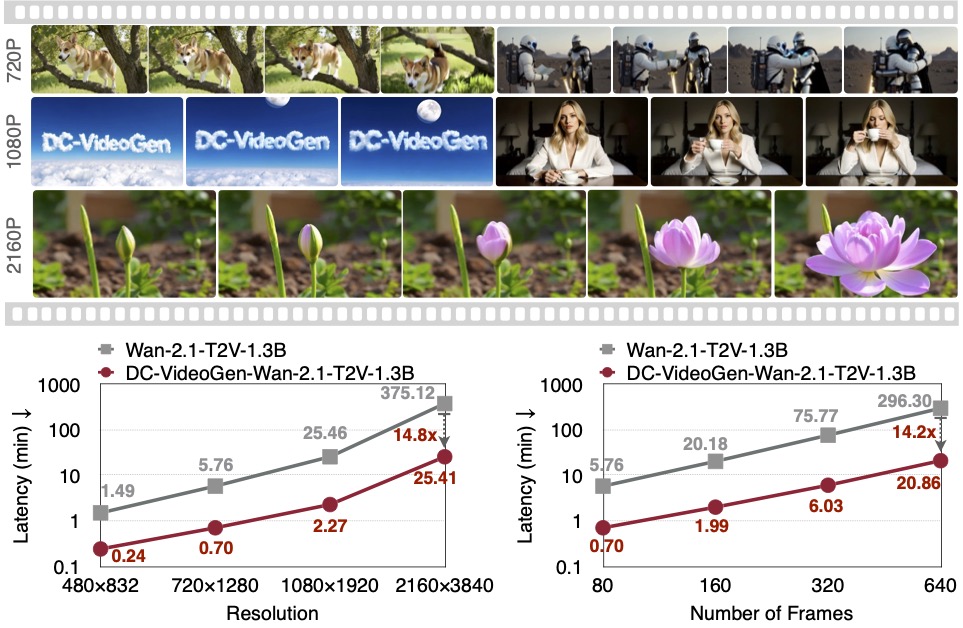
We introduce DC-VideoGen, a post-training acceleration framework for efficient video generation. DC-VideoGen can be applied to any pre-trained video diffusion model, improving efficiency by adapting it to a deep compression latent space with lightweight fine-tuning. The framework builds on two key innovations: (i) a Deep Compression Video Autoencoder with a novel chunk-causal temporal design that achieves 32x/64x spatial and 4x temporal compression while preserving reconstruction quality and generalization to longer videos; and (ii) AE-Adapt-V, a robust adaptation strategy that enables rapid and stable transfer of pre-trained models into the new latent space. Adapting the pre-trained Wan-2.1-14B model with DC-VideoGen requires only 10 GPU days on the NVIDIA H100 GPU. The accelerated models achieve up to 14.8x lower inference latency than their base counterparts without compromising quality, and further enable 2160x3840 video generation on a single GPU.
We introduce DC-VideoGen, a post-training acceleration framework for efficient video generation with a Deep Compression Video Autoencoder and a robust adapation strategy AE-Adapt-V.
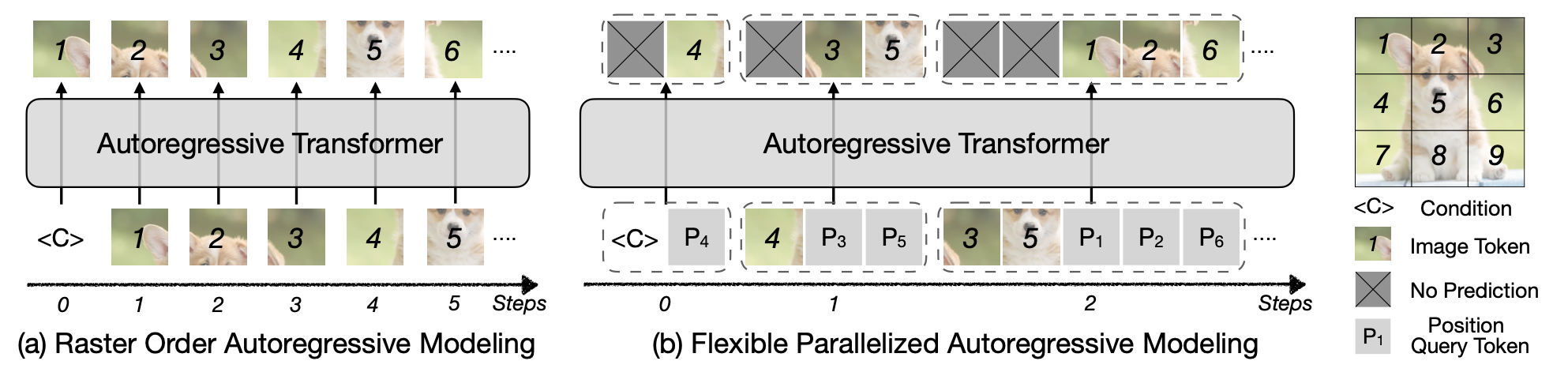
We present Locality-aware Parallel Decoding (LPD) to accelerate autoregressive image generation. Traditional autoregressive image generation relies on next-patch prediction, a memory-bound process that leads to high latency. Existing works have tried to parallelize next-patch prediction by shifting to multi-patch prediction to accelerate the process, but only achieved limited parallelization. To achieve high parallelization while maintaining generation quality, we introduce two key techniques: (1) Flexible Parallelized Autoregressive Modeling, a novel architecture that enables arbitrary generation ordering and degrees of parallelization. It uses learnable position query tokens to guide generation at target positions while ensuring mutual visibility among concurrently generated tokens for consistent parallel decoding. (2) Locality-aware Generation Ordering, a novel schedule that forms groups to minimize intra-group dependencies and maximize contextual support, enhancing generation quality. With these designs, we reduce the generation steps from 256 to 20 (256×256 res.) and 1024 to 48 (512×512 res.) without compromising quality on the ImageNet class-conditional generation, and achieving at least 3.4× lower latency than previous parallelized autoregressive models.
We introduce Locality-aware Parallel Decoding to accelerate autoregressive image generation and achieve 13× faster than traditional AR models and at least 3.4× faster than previous parallelized AR models.
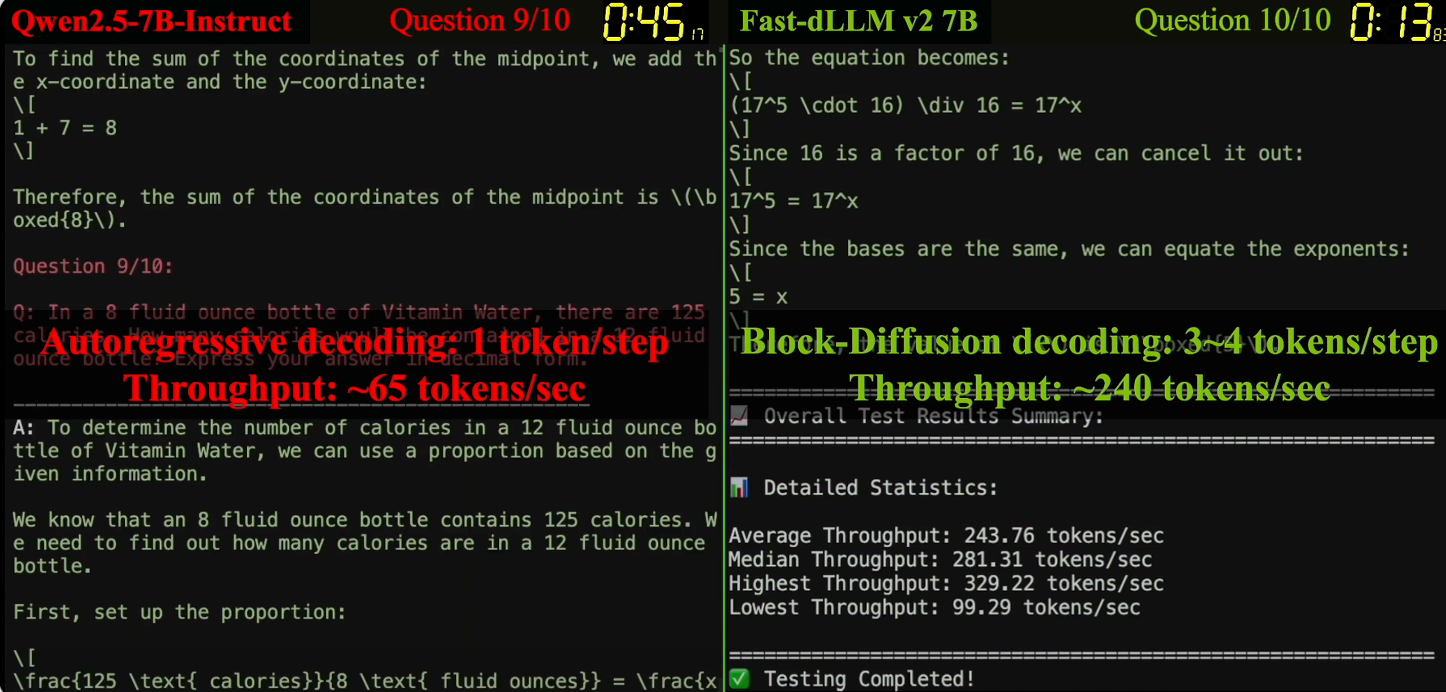
Autoregressive (AR) large language models (LLMs) have achieved remarkable performance across a wide range of natural language tasks, yet their inherent sequential decoding limits inference efficiency. In this work, we propose Fast-dLLM v2, a carefully designed block diffusion language model (dLLM) that efficiently adapts pretrained AR models into dLLMs for parallel text generation, requiring only approximately 1B tokens of fine-tuning. This represents a 500x reduction in training data compared to full-attention diffusion LLMs such as Dream (580B tokens), while preserving the original model's performance. Our approach introduces a novel training recipe that combines a block diffusion mechanism with a complementary attention mask, enabling blockwise bidirectional context modeling without sacrificing AR training objectives. To further accelerate decoding, we design a hierarchical caching mechanism: a block-level cache that stores historical context representations across blocks, and a sub-block cache that enables efficient parallel generation within partially decoded blocks. Coupled with our parallel decoding pipeline, Fast-dLLM v2 achieves up to 2.5x speedup over standard AR decoding without compromising generation quality. Extensive experiments across diverse benchmarks demonstrate that Fast-dLLM v2 matches or surpasses AR baselines in accuracy, while delivering state-of-the-art efficiency among dLLMs - marking a significant step toward the practical deployment of fast and accurate LLMs.
Our approach introduces a novel training recipe that combines a block diffusion mechanism with a complementary attention mask, enabling blockwise bidirectional context modeling without sacrificing AR training objectives.
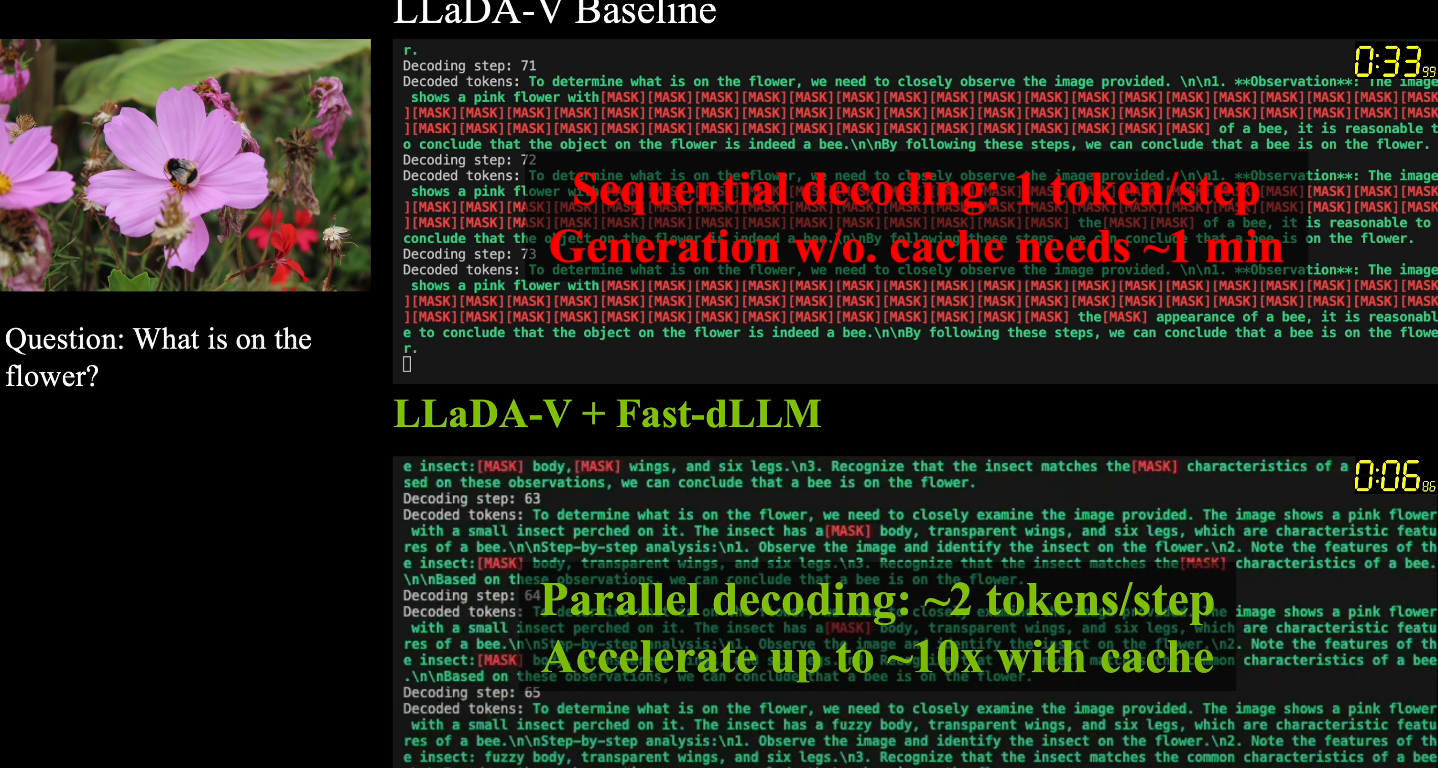
Diffusion-based large language models (Diffusion LLMs) have shown promise for non-autoregressive text generation with parallel decoding capabilities. However, the practical inference speed of open-sourced Diffusion LLMs often lags behind autoregressive models due to the lack of Key-Value (KV) Cache and quality degradation when decoding multiple tokens simultaneously. To bridge this gap, we introduce a novel block-wise approximate KV Cache mechanism tailored for bidirectional diffusion models, enabling cache reuse with negligible performance drop. Additionally, we identify the root cause of generation quality degradation in parallel decoding as the disruption of token dependencies under the conditional independence assumption. To address this, we propose a confidence-aware parallel decoding strategy that selectively decodes tokens exceeding a confidence threshold, mitigating dependency violations and maintaining generation quality. Experimental results on LLaDA and Dream models across multiple LLM benchmarks demonstrate up to 27.6x throughput improvement with minimal accuracy loss, closing the performance gap with autoregressive models and paving the way for practical deployment of Diffusion LLMs.
We introduce a novel block-wise approximate KV Cache mechanism tailored for bidirectional diffusion models, enabling cache reuse with negligible performance drop.
We actively collaborate with industry partners on efficient AI, model compression and acceleration. Our research has influenced and landed in many industrial products: Intel OpenVino, Intel Neural Network Distiller, Intel Neural Compressor, Apple Neural Engine, NVIDIA Sparse Tensor Core, NVIDIA TensorRT LLM, AMD-Xilinx Vitis AI, Qualcomm AI Model Efficiency Toolkit (AIMET), Amazon AutoGluon, Facebook PyTorch, Microsoft NNI, SONY Neural Architecture Search Library, SONY Model Compression Toolkit, ADI MAX78000/MAX78002 Model Training and Synthesis Tool.




