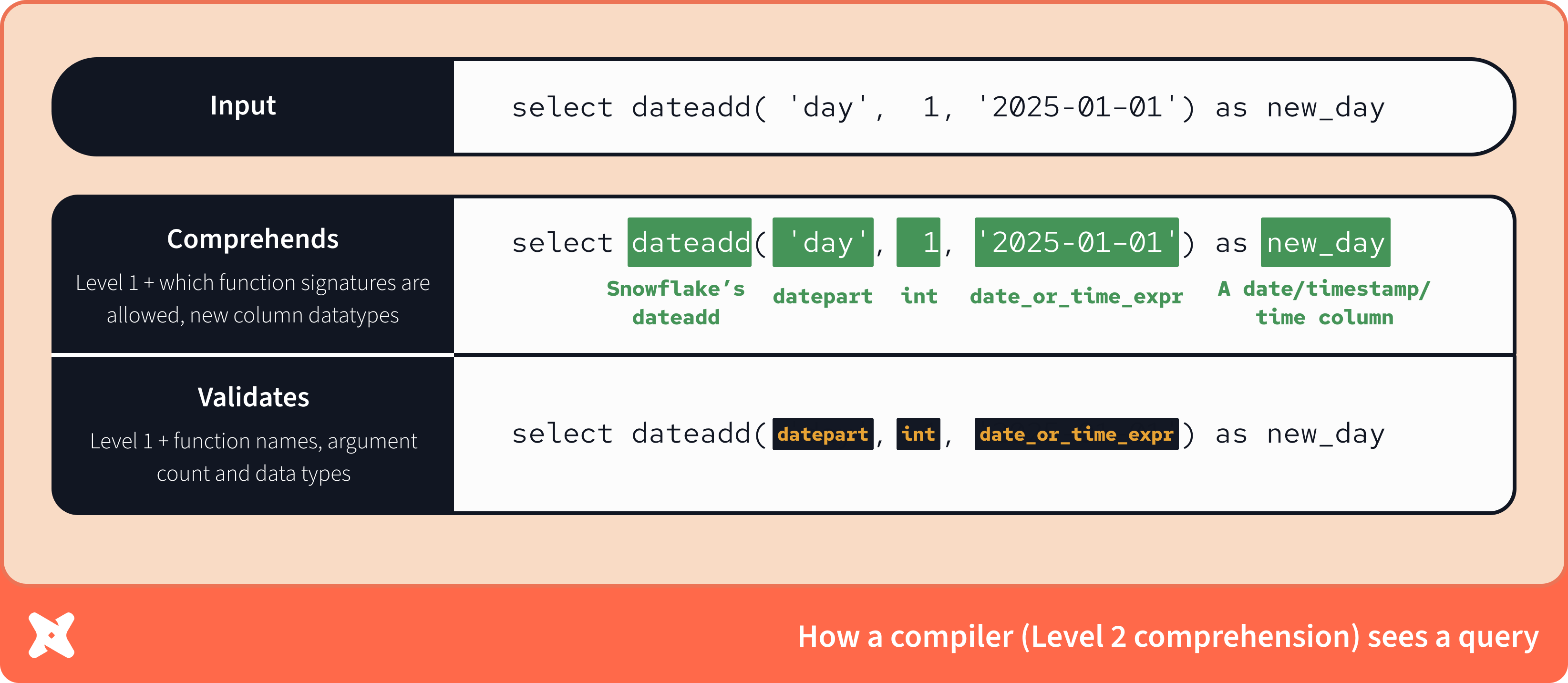
Today we released a collection of dbt agent skills so that AI agents (like Claude Code, OpenAI's Codex, Cursor, Factory or Kilo Code) can follow the same dbt best practices you would expect of any collaborator in your codebase. This matters because by extending their baseline capabilities, skills can transform generalist coding agents into highly capable data agents.
 dbt agent skills allow you to transform generalist coding agents into highly capable data agents
dbt agent skills allow you to transform generalist coding agents into highly capable data agentsThese skills encapsulate a broad swathe of hard-won knowledge from the dbt Community and the dbt Labs Developer Experience team. Collectively, they represent dozens of hours of focused work by dbt experts, backed by years of using dbt.
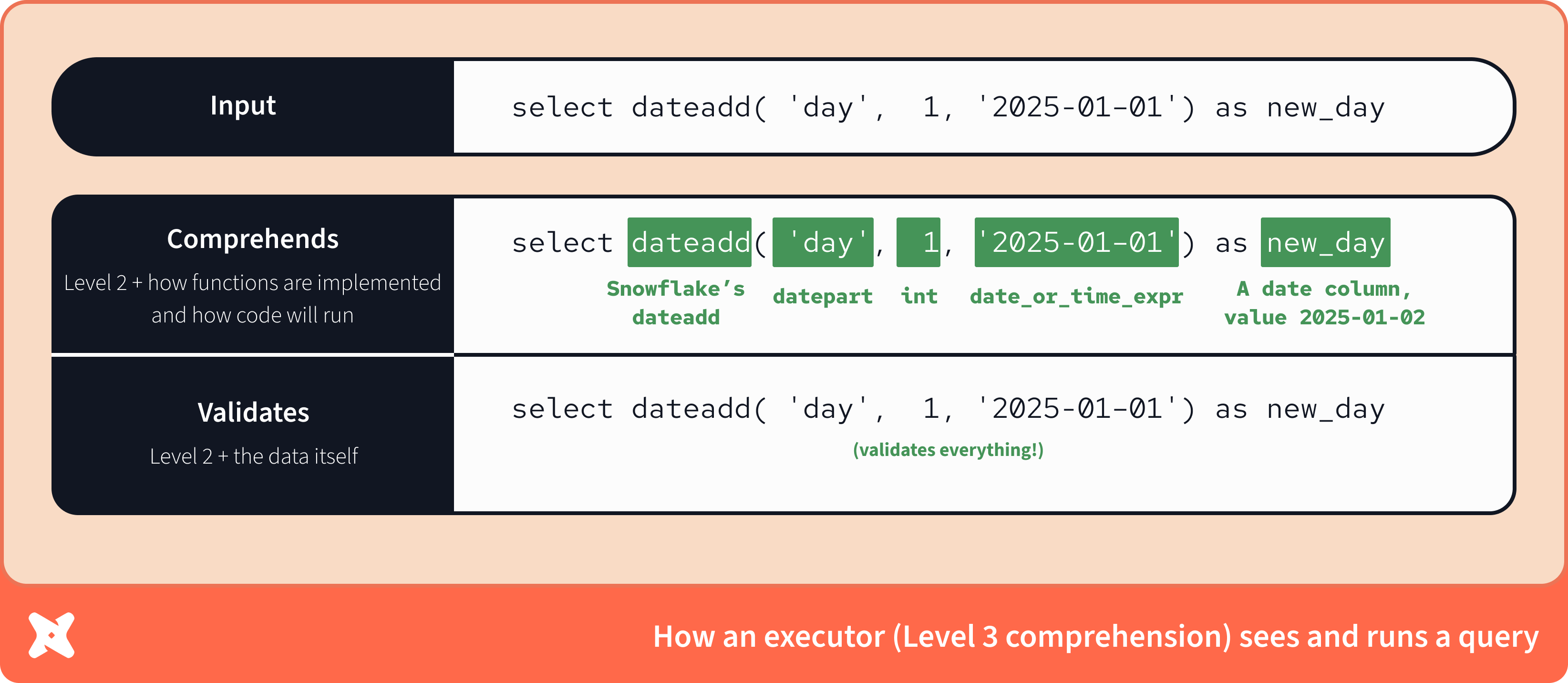
 With access to skills, agents like Claude take a systematic approach to tasks
With access to skills, agents like Claude take a systematic approach to tasksThe ecosystem is rapidly evolving for both authors of skills and the agents that consume them. We believe these skills are very useful today, and that they will become more useful over the coming weeks and months as:
- skills become better embedded into agent workflows, particularly increasing the rate at which they select the right skills to use at the right time
- wider community adoption and feedback improves the breadth and depth of available skills
What’s included
Our agent skills repo contains skills for:
- Analytics engineering: Build and modify dbt models, write tests, explore data sources
- Semantic layer: Create metrics, dimensions, and semantic models with MetricFlow
- Platform operations: Troubleshoot job failures, configure the dbt MCP server
- Migration: Move projects from dbt Core to the dbt Fusion engine
You’ll notice these skills vary in size of task and complexity. The primary using dbt for analytics engineering skill contains information about the entire workflow loop for analytics engineering. Other skills are more focused and task dependent.
We plan to continue refining these and adding more skills over time. If there’s a skill that would be useful that you don’t see, please open an issue on the repo.
Quickstart
1. Add the skills to your agent
In Claude Code, run these commands (one at a time):
/plugin marketplace add dbt-labs/dbt-agent-skills
/plugin install dbt@dbt-agent-marketplace
For agents other than Claude Code, use this command (requires Node to be installed):
npx skills add dbt-labs/dbt-agent-skills --global
or just manually copy the files you want into the correct path for your agent.
2. Start a new agent session
Restart your terminal to make sure the new skills are detected.
3. Try it yourself
Try giving an instruction like:
- Plan and build models for my new HubSpot source tables
- Work out why my
dbt buildjust failed - Write unit tests based on the requirements in this GitHub issue, then create a new model that passes
- Update
fct_transactionsto become a semantic model - Is there a difference in bounce rate for free vs paid email domains?
We focused on tasks that are either common (daily model building, debugging) or complex (semantic layer setup, unit testing edge cases). Each skill contains high-signal knowledge, and has been validated in real-world testing and against ADE-bench.
If you just want to get started today, you can stop reading now. But there’s a whole lot to say about what skills are, why they’re useful and how we expect them to plug into the dbt workflows of today and tomorrow.
Normal cautions around agentic coding apply. Please take appropriate safeguards, particularly when working with production or sensitive data.
So what is a skill, anyway?
You can think of skills as bundles of prompts (and scripts) which LLMs can dynamically string together to gain context or expertise on a given task.
In some ways, a skill is very simple - it’s a markdown file with a predefined structure. The venerable dbt_style_guide.md of yore would fit right in! It has a bunch of bulleted instructions, some sample code, and links out to other resources when necessary; the new Skills format does the same things. Anthropic introduced Skills in October 2025, and they are now an open standard adopted by 30+ agents.
A better question than what might be why. From the agent skills site:
Agents are increasingly capable, but often don’t have the context they need to do real work reliably. Skills solve this by giving agents access to procedural knowledge and company-, team-, and user-specific context they can load on demand.
Here’s an example skill from Anthropic:
 An example SKILL.md file for working with PDFs, which also contains references to more complex workflows to load on-demand
An example SKILL.md file for working with PDFs, which also contains references to more complex workflows to load on-demandHow do skills interact with MCP?
Another common question is how skills differ from MCP servers, and whether both are necessary.
- MCP is how you provide access to tools (especially remote tools requiring authentication)
- Skills are how you provide context and knowledge around using those tools
dbt Agent skills and the dbt MCP server are complementary, but you don’t have to use both to get value.
Consider the PDF example. Working with PDF files doesn’t require a MCP server, because the editing library can be installed locally. But you want that library to be used in a consistent way instead of the LLM inventing something from first principles every time.
So then why does the dbt MCP also have tools that call into the CLI? For interfaces that support MCP but not skills, it’s helpful to bake the specific way the CLI commands are called into the MCP server, but this is an open question and something we’re watching closely.
From generalist to specialist
To summarize, the best way to think of skills is as a layered training manual. If you took a very smart generalist off the street, what would they need to be able to use and implement your organization's workflows?
 Skills provide layered context that builds on an agent's baseline capabilities
Skills provide layered context that builds on an agent's baseline capabilitiesWhy skills matter
Skills allow you to embed complex process knowledge that is non-obvious to agents
Any experienced dbt practitioner will have a number of intuitions when working with a dbt project:
- You want to poke around a bit and get a sense of the schema and underlying data before making any changes. Read some docs, run a couple of
dbt showqueries, that sort of thing. - If you’re modifying an existing model, you need to look at the underlying data and get a sense of what columns live in upstream data sources.
- After making a new model or modifying one, you need to look at the data again, as well as run summary/aggregate statistics to see if it matches your expected shape and output
The current generation of coding agents tends to not do these things by default. Skills fix that by including broad dbt best practices like the ones above, but they can also provide very in-depth and nuanced guidance through supplemental reference materials, such as:
- Warehouse-specific configurations, like avoiding full table scans on BigQuery when discovering data
- Variations based on the specific dbt version or engine you’re using;
dbt compilecan detect many SQL errors when invoked from the dbt Fusion engine, but dbt Core needs to rundbt buildfor the same result.
Skills can also evolve at a faster pace than frontier AI model releases, making it easier to update guidance and adapt to changes in the dbt authoring layer. We recently revamped the authoring experience for semantic models; by including a skill that knows about the new syntax, we can stop your agent from using the old syntax even though that’s the majority of training data online.
Skills protect against plausible but incorrect output
If you ask an LLM to add some tests to your model, it might add an accepted values test. dbt’s documentation on accepted_values tests contains an example saying that the right values on an order_status column are ['placed', 'shipped', 'completed', 'returned'], and we’ve seen some models replicate this or otherwise hallucinate potential column values.
With a skill, you can instruct the agent to preview the data before writing tests to ensure that the output matches the real data in your warehouse.
Skills allow you to give opinionated guidance to agents
Beyond global best practices, there are also a number of opinionated decisions inside of a given team’s dbt project:
- What types of data tests should I have on my models?
- When should I use the Semantic Layer vs. SQL for natural language questions?
- How should the project be structured (stg/int/mart? Medallion? Data vault?)
Our current skills are only semi-opinionated - they have opinions on how and where you should apply your data tests but not on whether you should use dbt’s recommended project structure or style guide. In the future we anticipate that we will release first party opinionated guides on project and code structure and that there will be a thriving ecosystem of opinionated community-sourced skills on different dimensions of data work.
Skills allow you to give non-public information to agents
In addition to adopting our skills, you should add some of your own.
Taking a smart generalist across all disciplines and turning them into a smart generalist with a specialization in dbt still isn’t enough. They also need to become a specialist in the way your company does data.
Obviously we can’t include those in our general best practices skills, but this is where the composability of skills comes in. You can add context about your company, your data, the specific ins and outs and nuances of interacting with your systems, and expect it to augment what we provide.
Examples of questions you might like to answer in your skills:
- Have any default macros been overridden in my organization’s project?
- What is my organization’s cross-project or cross-platform mesh strategy?
- What partitioning rules should be applied to new models for a given usage pattern?
More to come soon on how we might support org level skills within dbt projects.
How we validated the dbt Agent Skills
It can be challenging to assess the performance of AI workflows. There are many different ways to do this and all of them are imperfect, so we have settled on a multilayered strategy for ensuring our agent skills behave the way we want them to.
Careful expert generation and curation of skills
While we did have some LLM assistance in generating some of the skills, these are very much not "oneshotted outputs". Each skill represents hours of crafting, reviewing and refining by world class dbt experts to ensure that our knowledge has been accurately encoded into the skills. Data work has a lot of tacit knowledge and edge cases, and this is where skills really shine.
Hands-on testing of each skill in real life examples
Nothing beats hands-on usage and so we’ve tested each skill to see how it performs in real use cases. This has helped us tune the performance and identify non-obvious gaps in our instructions.
We were particularly thrilled when we asked the agent to make performance recommendations on one of the largest tables in our dbt project, with and without the skill. While both results gave plausible recommendations, the recommendations with the skill were more tailored and relevant to our use case as determined by our internal data team.

Custom suite for A/B testing skills
We developed a system for rapidly comparing different tool combinations (MCP + skills, skills alone, no tools) to understand how they changed an agent’s output.
This library allows testing how variations of skills perform for a given scenario and reviewing in detail the skills and tools called by the agent.
We provide context to Claude Code (e.g. a dbt project or some YAML files) and we ask it to solve a problem with different setups:
- with different variations of a skill
- with or without a MCP server connected
- explicitly prompting the agent to use a skill, or leaving it to discover it solo
We can then either manually compare the conversations (which skills were called, what output was produced), or ask Claude Code to rate the different runs automatically.
One thing we discovered in this process is that Claude is much less willing to use skills in "headless" CLI invocations than "interactive" ones where a user is talking back and forth. Because of this, we felt comfortable including the explicit prompt in benchmarking tasks.
Benchmarking against ADE-bench
We also ran through the ADE-bench tasks to assess performance with and without skills. While not every skill has corresponding tasks in the benchmark (yet!), this provides helpful signal, particularly on the primary analytics engineering skill.
We saw modest improvements in performance on the benchmark with Skills, rising from a 56% accuracy rate without skills to a 58.5% accuracy rate with Skills. But the bigger story is not the headline numbers, but the individual tasks that were solved with skills that previously had 0% success rates.
Notably, we found significant benefits in tasks which require iterative work on top of a dbt DAG, which is one of the most common failure points we've experienced in using coding agents with dbt.
Without skills

With skills

For example, when asked to produce multiple models based on their schema.yml definition, the baseline agent created 6 models at once and declared victory. The skill-using agent worked iteratively, and successfully completed the task every time.
On the other hand, encouraging DRY principles led to the skill-using agent intermittently reusing a column with a logic bug in this task, where the baseline agent noticed and corrected the bug.
Where there are gaps
Today, skill loading can be a little hit-and-miss. As with everything in AI, things are moving fast, and skills are seeing widespread adoption, so we don’t think that’s going to be a long term issue. We’d also love to see stronger and more reliable cross-skill referencing, such as what’s described here.
Again: you should go try this yourself
Here’s the repo, with installation instructions in the readme.
Agent skills have tremendous bang-for-buck for procedural tasks, especially considering how easily you can get started. We’re excited to see many people from across the Community trying them on real-world workflows, and building new skills of their own.
We’re also exploring ways to enable tighter integration between dbt and agent skills, as well as making it easier to manage custom skills for your specific dbt project and data.
The best way to stay involved is to share what you're discovering in #topic-agentic-analytics on Slack or to open up issues on the GitHub repo.
]]>