使用入门
客户案例









为什么选择 Google Cloud 进行数据科学工作
Google Cloud 统一的数据与 AI 平台
提高业务速度与敏捷性,创造短期和长期价值。
3 倍
更经济高效,数据移动量降至最低
4 倍
更快速地完成模型训练、微调与部署
10 倍的
降低 AI 成本,从而使 ROI 目标更易达成
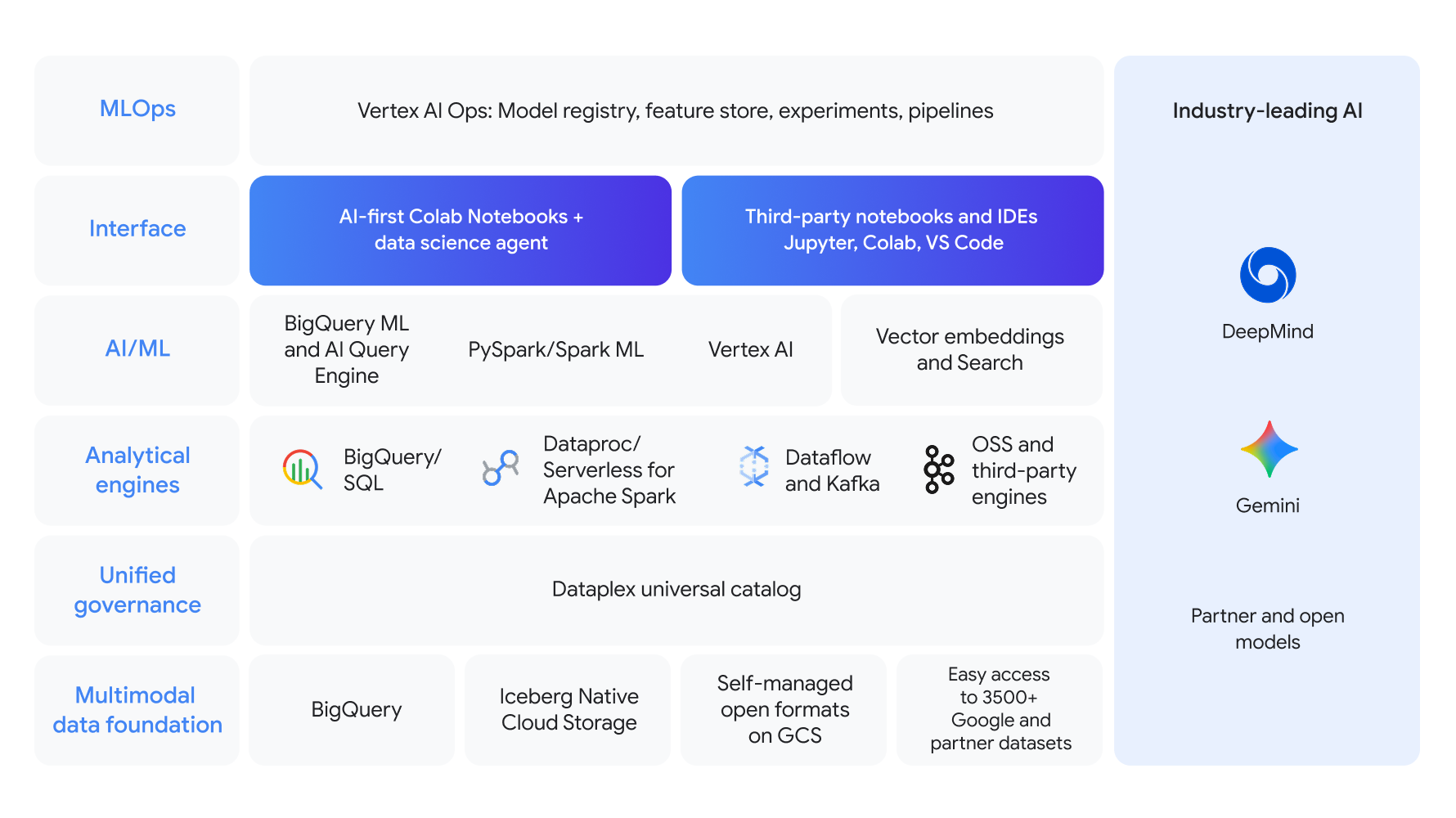
面向端到端数据科学工作流的统一平台
基于多模态数据基础构建,为整个数据科学和机器学习生命周期提供统一的解决方案,并确保统一治理。借助 BigQuery SQL 和 Spark 等强大的分析引擎,再使用 BigQuery ML 或 Vertex AI 构建模型。借助 AI 优先的 Colab Enterprise 笔记本和强大的 MLOps,在行业领先 AI 技术的支持下简化开发流程。
以 AI 优先的笔记本为核心的集中式工作区
从一系列适用于企业数据科学的笔记本解决方案中进行选择。Colab Enterprise 提供安全、受管理的集成环境,可与 Vertex AI 和 BigQuery 集成。Vertex AI Workbench 提供可自定义的 JupyterLab 实例,而 Cloud Workstations 支持完整的 IDE。扩展程序还可以将自托管工具直接连接到 Google Cloud 服务。


集成式数据科学代理
借助智能体能力,加速数据科学开发,促进数据探索、转换与机器学习建模。先用通俗英文给出高层目标,随后数据科学智能体将生成详尽计划,涵盖数据科学建模的各个环节:数据加载、探索、清理、可视化、特征工程、数据拆分、模型训练/优化与评估。

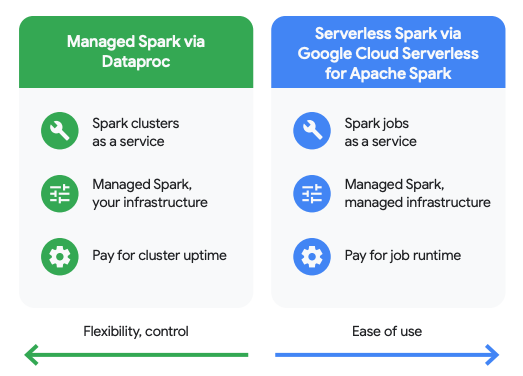
使用多个引擎灵活处理数据
可任选处理引擎——无论是 BigQuery 的 SQL 引擎,还是 Apache Spark 等开源框架——直接在单一且统一的数据副本上工作。由此无需为不同系统维护多份独立数据副本。
借助适用于 Python 的 BigQuery DataFrames 扩展数据科学工作
更偏好 Python 原生库吗?BigQuery DataFrames 提供类 pandas 的 API,可将 Python 代码转换为优化后的 SQL,并在 BigQuery 引擎上执行。因此,您可灵活选用最合适的工具——无论是 SQL、PySpark,还是 pandas 风格的 DataFrame——同时始终基于同一底层数据工作。

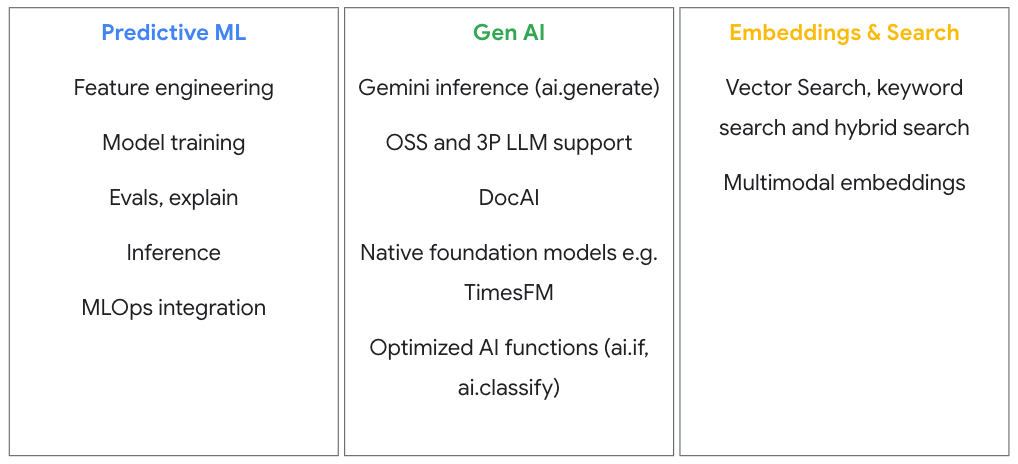
构建、训练、调优和运行机器学习模型
使用 SQL 借助 BigQuery ML 构建、训练、评估并部署模型,无需移动数据。利用内置预训练模型,或通过 SQL 函数调用 Gemini,完成数据分析/丰富。对于自定义模型,Vertex AI 支持 PyTorch、TensorFlow 等主流机器学习库。无缝集成使您可在 BigQuery 中进行特征工程、在 Vertex AI 中进行自定义模型训练,并通过 SQL 回到 BigQuery 完成推理。